
Sťahovanie súpisných hárkov zo Slovakiana
Keďže ste mi viacerí písali aby som sem umiestnil návod ako sťahovať súpisné hárky zo Slovakiana tak som sa rozhodol vašej žiadosi vyhovieť. Návod nie je ľahký ako som vám tvrdil ale je funkčný. Pokoaľ vás pre genealogický výskum zaujíma iba jeden hárok, pokojne tento návod vynechajte a sníku si stiahnite inak. Ak ale spracúvate celé mestá a obce tak ako ja, v takom prípade oceníte keď máte snímky offline u seba. Výhodou je rýchlejšie listovanie medzi obrázkami. Po dohode vám viem súbory stiahnuť a vyzdieľať.
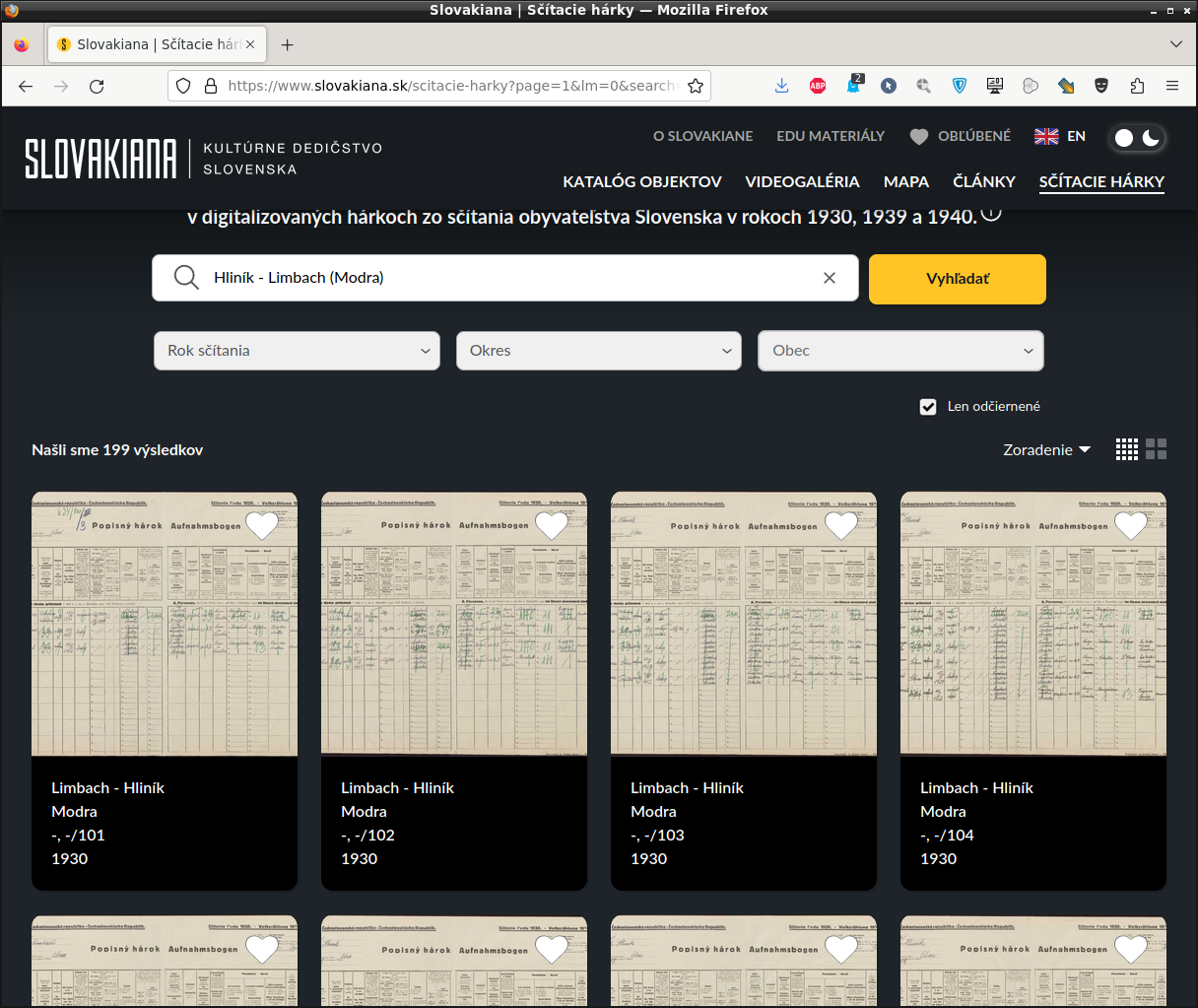
Z tohto oka je pre shiahnutie potrebné iba URL počet snímkov, v tomto prípade 199 a samozrejme názov obce. Týmito hodnotami vhodne naplňte nasledujúci skript.
curl -s -G -H "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Firefox/115.0"
-H "Accept: application/json, text/plain, */*"
-H "Referer: https://slovakiana.sk/"
-H "Origin: https://slovakiana.sk"
-H "DNT: 1"
--data-urlencode "searchText=Limbach - Hliník"
"https://wcm.slovakiana.sk/censussheet/search?size=200&page=0&onlyUnBlackened=true"
-o Limbach.jsonSúbor Limbach.json je teraz plný údajov ktoré v zásade nepotrebujeme ale zato sú tam aj identifikátory ktoré sú potrebné k ďalšiemu postupu.
grep -o '"key":"cair-[^"]*"' Limbach.json | sed -E 's/"key":"(cair-[^"]*)"/https:\/\/slovakiana.sk\/scitacie-harky\/\1/' > import.txtTýmto postupom získame súbor import.txt s kompletnými podstránkami pre danú obec v tvare "https://www.slovakiana.sk/scitacie-harky/cair-ko1d0rw"
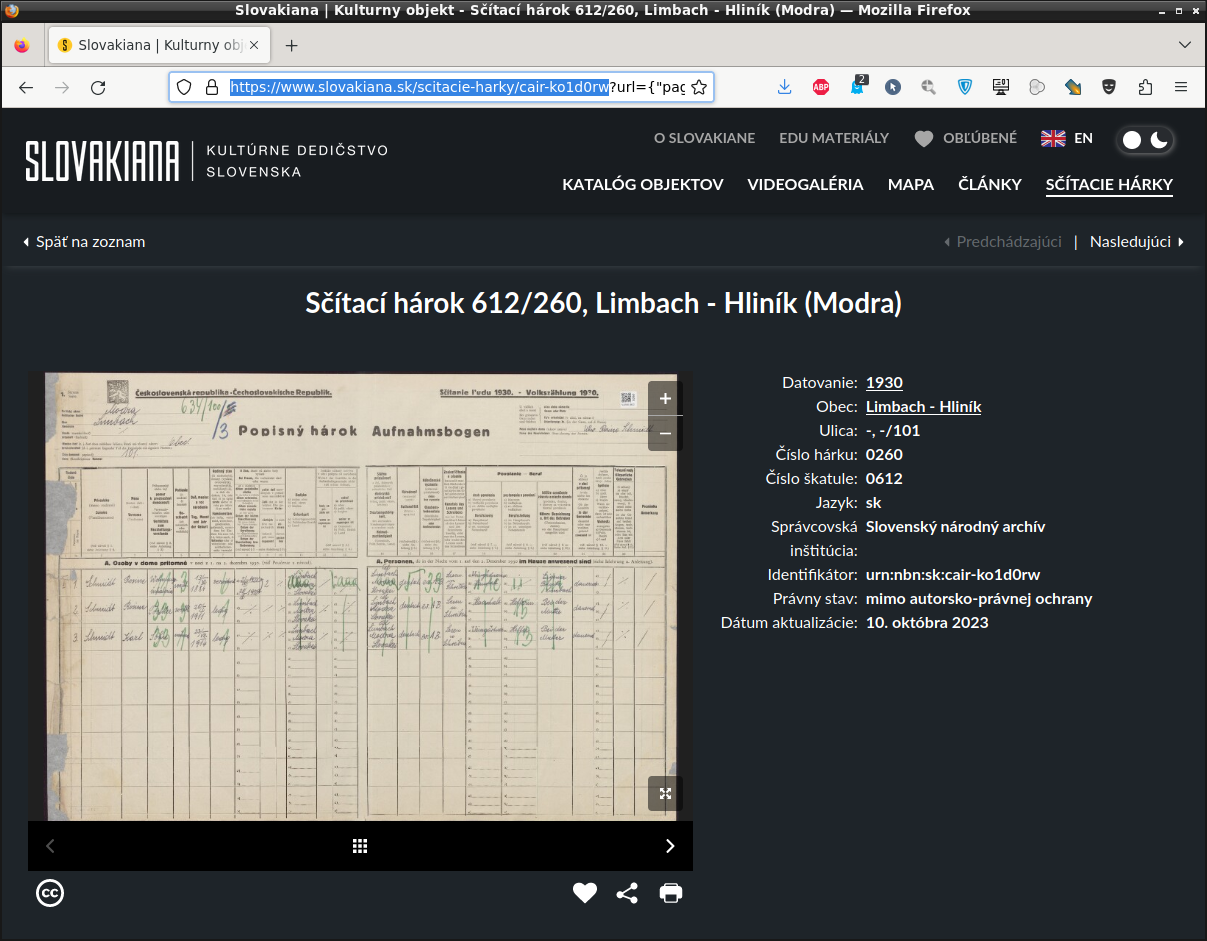
Vytvorte si spustitelný bash skript napriklad slovakiana.sh vložte nižie umiestnený kód a spustite. Získate tak súbor export.txt obsahujúsi všetky url
#!/bin/bash
input_file="import.txt"
output_file="export.txt"
# Vycisti export.txt pred zapisom
echo "" > "$output_file"
while IFS= read -r line; do
# Ziskanie ID z URL
object_id=$(basename "$line")
# Ziskanie doid-XXXXX
doid=$(curl -s "https://wcm.slovakiana.sk/culturalobject/$object_id" | jq -r '.digitalObjects[].id')
if [[ -n "$doid" ]]; then
# Ziskanie URL adries
urls=$(curl -s "https://wcm.slovakiana.sk/digitalobject/$doid" | jq -r '.content[] | select(.type=="IMAGES") | .images[].full.fileUrl')
# Zapis do suboru
echo "$urls" >> "$output_file"
else
echo "Chyba: Nepodarilo sa ziskat doid pre $line" >&2
fi
done < "$input_file"
Teraz už iba posledný krok a to stiahnuť súbory.
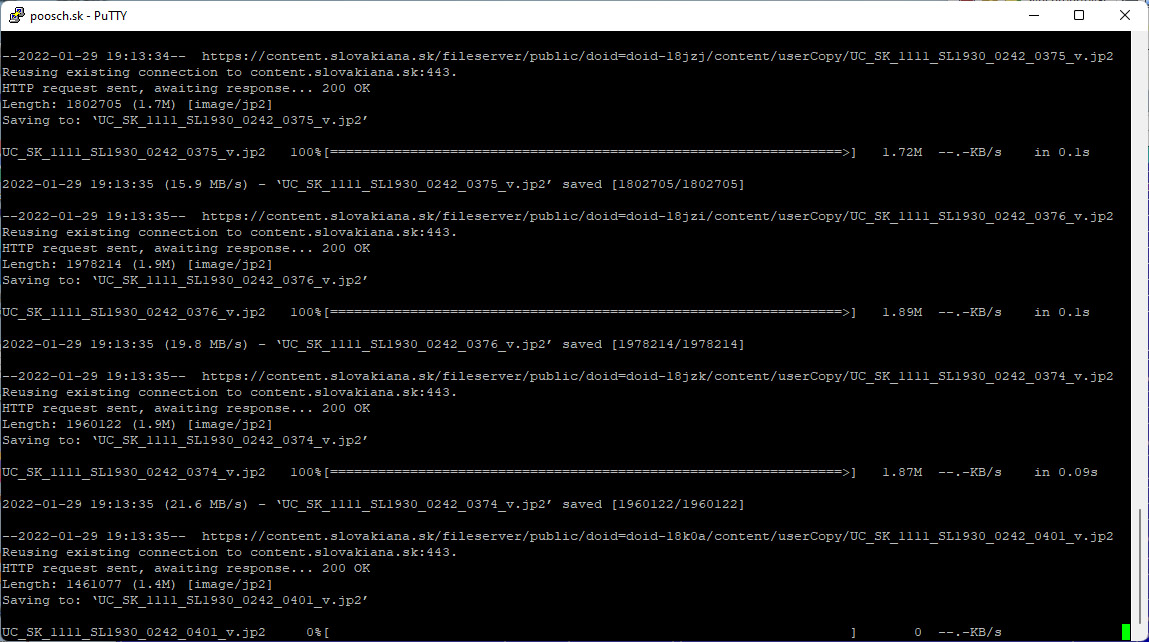
wget -i export.txtStiahnuté obrázky viete prezerať cez IrfanView a pluginom na zobrazenie jpeg2000
Strarý už nefunkčný postup
Tento návod už nie je funkčný odkedy Slovakiana prepracovala web. Tým ktorým postup pomohol gratulujem. Ak máte vyextrahované pôvodné url k jp2 obrázkom tak sťahovanie je naďalej možné. Nový postup stiahnutia už nie je tak jednoduchý pre verejnosť a tak nemá zmysel ho publikovať. Vyhľadávanie už majú na lepšej úrovni takže pokračujte Slovakiana
Moravská obdoba je napríklad: Moravský zemský archív. Ten je v mnohom lepší a rýchlejší. Navyše obsahuje aj sčítacie operáty z 19-tého storočia.
Stránka Slovakiana uvoľnila sčítacie hárky z roku 1930 bez začiernenia a z roku 1940 so začiernením citlivých informácii. Keďže prehliadanie obcí bolo pre mňa zdĺhavé potreboval som mať snímky uložené na lokálnom disku. Dlhšiu dobu som uvažoval, ako sa k snímkom dostať, aby som nemusel robiť printscreeny obrazovky a jednotlivo ich ukladať. Po konzultácii s priateľom som zistil, ako sú snímky pomenované a následne som vytvoril postup, ako ich viem stiahnuť. Postup uvádzam nižšie. Keďže sú obrázky vo formáte JPEG 2000 a nie je možné zobraziť ich priamo vo Windowse používam na prezewranie Irfan View s nainštalovaným pluginom JPEG2000. Slovakina urobila veľký kus práce pri naskenovaní hárkov. Je však veľkou škodou, že vyhľadávanie cez web nie je ľahké a prehliadanie rýchlejšie.
Ak by bol v budúcnosti web slovakiana rýchlejší tak tento postup by nebol potrebný. Ďalšou nevýhodou je, že snímky nie sú uložené podľa súpisného čísla, čo pri väčších obciach spôsobuje problém pri prezeraní.
Ako prvé potrebujete stiahnuť zoznam snímkov. Ja na to používam prehliadač Mozilla Firefox, kde sa po slačení F12 dostanem k analýze sieťovej aktivity. Podľa prvého snímku si nastavím filter na zobrazenie obrazových súborov a výsledok po načítaní uložte ako HAR. Toto urobím pre všetky stránky, kde mám zapnutý najvyžší počet súborov.
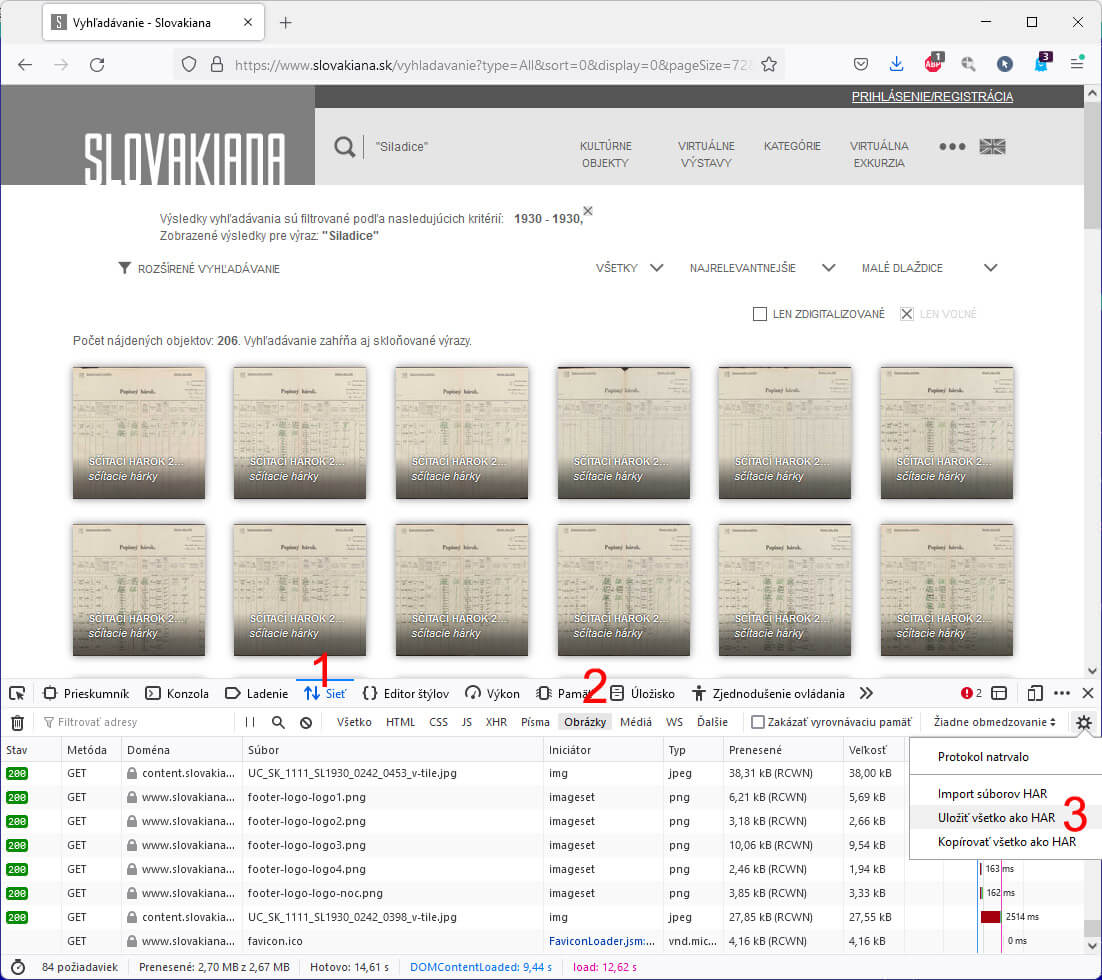
Po stiahnutí HAR súborov vyextrahujem všetky URL k obrázkom. Možností je viacero, a ja rád používam bash v linuxe. Tí z vás, ktorí nie ste v linuxe zbehlí možno budete vedieť napísať iný
postup ktorý by som tu mohol uverejniť.
Z HAR súborov vyextrahujem príkazom cat a grep url snímkov a uložím ich ako front.txt:
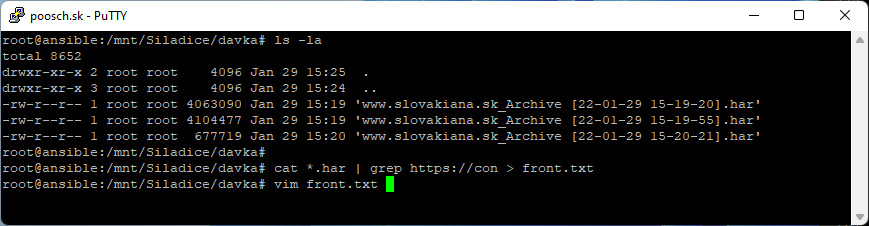
Pomocou programu vim editujem súbor front.txt a vymažem všetko, čo je pred http. V druhom kroku v tom istom súbore zmažem v-tile.jpg a nahradím ho v.jp2. Zmeny zapíšem a uložím.
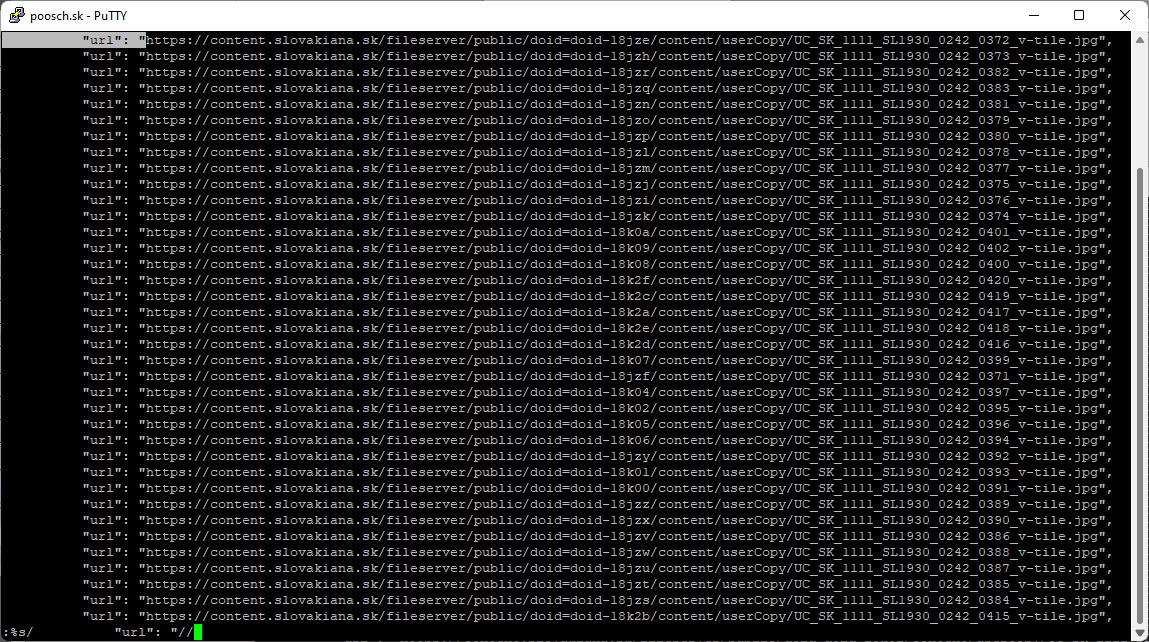
V tomto kroku potrebujem skopírovať front.txt na rear.txt. Substitúciou nahradím _v.jp2 na _r.jp2 a uložím. Oba textové súbory uložím do jedného s názvom dávka.
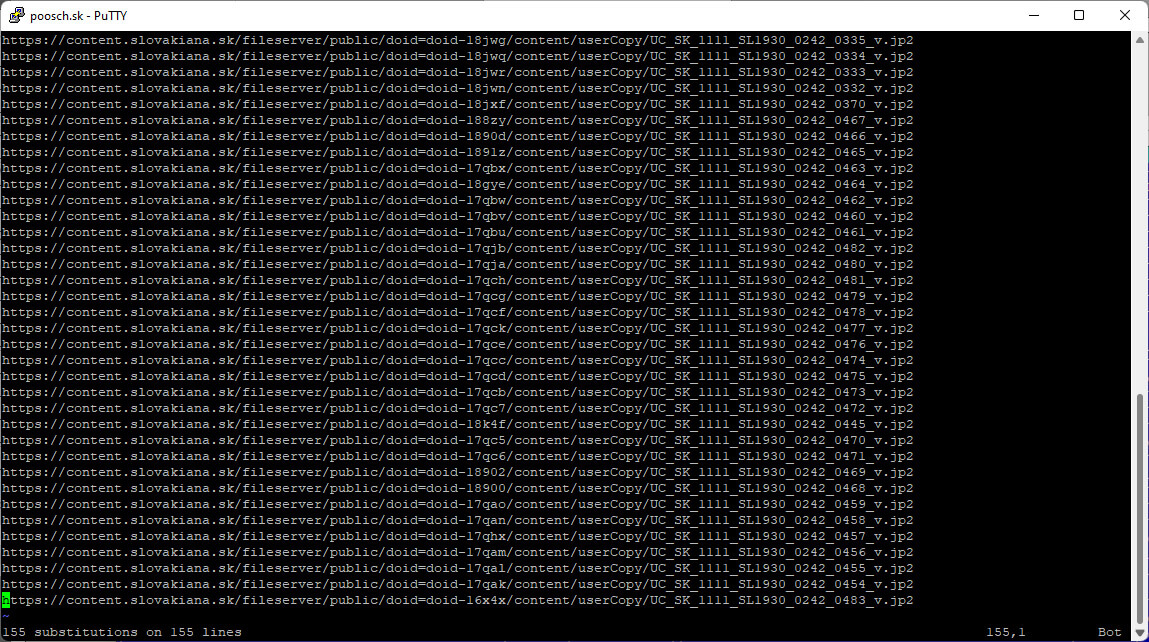
Teraz mi už nič nebráni, aby som s príkazom wget stiahol všetky snímky, ktoré obsahuje súbor dávka.
Zoznam Slovenských miest
Nižšie uvádzam zoznam miest s uvoľnenými sčítacími hárkami. V pomenovaniach obcí je viacero záludnosti, ktoré vedú k podobnému alebo zhodnému výsledku.
Mestá sú uvádzané podľa vtedajšej štruktúry miest pod väčšie okresné mestá. Ak nejaké mesto neviete nájsť, pretože v roku 1930 bol názov úplne odlišný hľadajte pod väčšími mestami po rozkliknutí.
-
Bánovce nad Bebravou
Bánovce nad Bebravou
Biskupice
Bobot
Bobotská Lehota
Borčany
Bošianska Neporadza
Brezolupy
Cimenná
Čierna Lehota
Čuklasovce
Dežerice
Dolné Držkovce
Dolné Motešice
Dolné Naštice
Dolné Ozorovce
Dolnie Držkovce
Dolnie Motešice
Dubnička
Dubodiel
Dvorec
Farkaška
Haláčovce
Horňany
Horné Držkovce
Horné Motešice
Horné Naštice
Horné Ozorovce
Hornie Držkovce
Hornie Motešice
Hornie Naštice
Chudá Lehota
Jastrabie
Kostolné Mitice
Krásna Ves
Kšinná
Latkovce
Letkovce
Libychava
Lutov
Ľutov
Malá Hradná
Malé Hoste
Malé Chlievany
Malé Ostratice
Miezgovce
Omastiná
Otrhanky
Otrhánky
Pečeňany
Pečňany
Peťovka
Petrova Lehota
Petrová Lehota
Podlužany
Pochabany
Pravotice
Prusy
Radiša
Rožnova Neporadza
Rožňova Neporadza
Rožnové Mitice
Ruskovce
Rybany
Slatina nad Bebravou
Slatinka nad Bebravou
Slovensko
Svinná
Šipkov
Šípkov
Šišov
Timoradza
Trebichava
Trebychava
Uhrovec
Uhrovské Podhradie
Veľká Hradná
Veľké Hoste
Veľké Chlievany
Veľké Ostratice
Vysočany
Závada
Zemianske Mitice
Zlatníky
Žitná
-
Banská Bystrica
Badin
Badín
Baláže
Banská Bystrica
Banská Bystrica – mesto
Bečov
Čačín
Dolná Mičiná
Donovaly
Dúbravica
Garansek
Harmanec
Hiadeľ
Horná Mičiná
Horná ulica
HornáRadvaň nad Hronom
Horné Pršany
Hriadeľ
Hrochoť
Humanec
Jabriková
Kalište
Kordíky
Kostiviarska
Kostriviarska
Králiky
Kráľová nad Hronom
Kráľová Nová Ves
Kremnička
Kuzmányho
Kyncelová
Kynceľová
Ľubietová
Lučatín
Lukavica
Lupčianska Udiča
Majer
Malachov
Moštenica
Motyčky
Môlča
Nemce
Oravce
Podhlavice
Podkonice
Podlavice
Ponická Huta
Poniky
Povrazník
Priechod
Prieloh
Radvaň nad Hronom
Rakytovce
Rakytovec
Riečka
Rudlová
Sásová
Sebedín
Selce
Senica
Skubín
Slovenská Lupča
Slovenská Ľupča
Staré Hory
Stoličková
Svätý Jakub
Šajba
Šalková
Špania – Dolina
Tajov
Ulmanka
Vlkanová
-
Banská Štiavnica
Baďan
Baďaň
Banská Štiavnica
Banská Štiavnica a Banská Belá
Beluj
Dekýš
Hodruša
Ilija
Klastava
Kolpachy
Kopanica
Kozelník
Močiar
Piarg
Počuvadlo
Počúvadlo
Prenčov
Sitnianska
Sitnianská
Svätý Antol
Teplá
Veľké Krškany
Vysoká
Žakýl
Žakýľ
-
Bardejov
Abrahámovce
Andrejová
Bardejov
Bardejovská Nová Ves
Bartošovce
Becherov
Beloveža
Bogliarka
Brezovka
Bucľoviany
Cigelka
Cígelka
Čarno
Dlhá Lúka
Fricka
Frička
Fričkovce
Gaboltov
Gerlachov
Hažlin
Hažlín
Hertník
Hervartov
Hrabovec
Hrabské
Hutka
Janovce
Jedlinka
Kľušov
Kobyly
Komárov
Komloša
Krivé
Križe
Kríže
Kružlov
Kružlov – Huta
Kružlová Huta
Kurov
Lenartov
Lipová
Liptovská Huta
Livov
Livohuta
Lukavica
Lukov
Lukov – Mlynská
Lukov nad Topľou
Malcov
Mokroluh
Niklová
Nižná Poľanka
Nižní Tvarožec
Nižnia Voľa
Nižný Tvarožec
Ondavka
Ortutova
Ortutová
Osikov
Petrová
Regetovka
Rešov
Rokytov
Rychvald
Slovenské Raslavice
Smilno
Snakov
Stebnícka Huta
Stebnícká Huta
Stebnik
Stebník
Sveržov
Šašová
Šiba
Tarnov
Tročany
Uhorské Raslavice
Vaniškovce
Varadka
Venecia
Vyšná Poľanka
Vyšňa Polianka
Vyšnia Voľa
Vyšný Tvarožec
Zborov
Zlaté
-
Bratislava
Agátky Stupava
Bašta
Baštová
Bethovenová
Biskupice pri Dunaji
Bratislava
Bratislava – mesto
Bratislava mesto
Bratislavska
Bulharská
Čeklís
Devín
Devín – Karlova Ves
Devínska Nová Ves
Dobytčie trh.
Dobytčie tržište
Dr. Blaho ul.
Dúbravka
Dunaj
Dusilová
Dutkova
Farná
Farského
Floriánská
Gunduličova
Güntherova
Hlboká
Hochštetno
Holubyho
Horvatský Grob
Horvátsky Grob
HostinecStupava
Ivanka pri Dunaji
Ivánka pri Dunaji
Jaskový rad
Jaskový rád
Jiraskovo Nabrežie
Jiringerova
Kapucínska
Karlova Ves
KlarisskáBratislava
Kúpeľná
Lamač
Lamačská cesta
Lazaretská
Lessingová
Mamatejova
Marianka
Mást
Mlýnská dolina
Na vršku
Nám. Republiky
Námestie republiky
Nemecká Pivnica
Neštich
Neštych
Nová Schönbergová
Obilné nám.
Öhlroeingarten
Pajštún
Palisady
Palisády
Petržalka
Píla
Polln
Prayová
Prievoz
ra
Rača
Račištorf
Račištorfská cesta
Riegerova
Simonyo riad
Staničná
stát.dráhyBratislava
Steinzatz
Stredná mlýn. dolina
Stupava
Suché mlýny
Svätý Jur
Šafarikovo námestie
Šimonyho rad
Šimonyo riad
Špitálska
Štefaniková
Tehelné pole
Törökova
Trnavská cesta
u St. prachárny
U suchého mlýna
Uhorská
Vajnorská
Vajnorská cesta
Vajnory
Vazová
Vinohrady Stupava
Wienerstrasse
Záhorská Bystrica
Zámocká
Zámocká
Zohor
Železničárská
-
Brezno nad Hronom
Bacuch
Bacúch
Beňuš
Brezno nad Hronom
Brusno
Bujakovo
Bystrá
Čierny Balog
Dolná Lehota
Dubová
Heľpa
Horná Lehota
Hronec
Chmelinsová
Jarabá
Jasenice
Jasenie
Lopej
Medzibrod
Michalová
Mýto pod Ďumbierom
Nemecká
Osrblie
Pohorelá
Polhora
Polomka
Predajná
Ráztoka
Ráztoky
Svätý Ondrej nad Hronom
Šumiac
Telgart
Telgárt
Valaská
Zámostie
Závadka nad Hronom
-
Bruck an der Leitha
Devín
Petržalka
-
Čadca
Čadca
Čadca – mesto
Čierne
Čierné
Horelica
Makov
Olešná
Oščadnica
Podvysoká
Raková
Skalité
Staškov
Svrčinovec
Turzovka
Vysoká nad Kysucou
Vysoká nad Kysucov
Zákopčie
-
Dobšiná
Čierna Lehota
Veľká Poloma
-
Dolný Kubín
Beňová Lehota
Bziny
Dlhá
Dlhá nad Oravou
Dolná Lehota
Dolný Kubín
Horná Lehota
Chlebnice
Istebné
Jasenová
Kňažia
Kraľovany
Krivá
Leštiny
Malatina
Malatiná
Malý Bysterec
Medzibrodie nad Oravou
Medzihradné
Mokraď
Oravský Podzámok
Osádka
Párnica
Pokryváč
Poruba
Porubá
Pribiš
Pribíš
Pucov
Revišné
Sedliacka Dubová
Sedliarska Dubová
Srňacie
Valaská Dubová
Veličná
Veľký Bysterec
Vyšný Kubín
Zábreš
Zábrež
Záskalie
Zaškov
Zázrivá
Žaškov
-
Dunajská Streda
Amadeovské Korčany
Asentofa
Baka
Baloň
Beketfa
Benkova Potôň
Beš
Blažov
Bodak
Bögellö
Cséfa
Csenkeszfa
Csentőfa
Čečínska Potôň
Čilizská Radvaň
Čilizský Ňárad
Dercsika
Dolná Potôň
Dolní Bar
Dolní Ňáražd
Dolní Štál
Dolnia Potôň
Dolný Bar
Dolný Ňáražd
Dolný Štál
Duly
Dunajská Streda
Eperjes
Etreove Korčany
Hegybeneéte
Hodos
Horná Potôň
Horné Mýto
Horní Bar
Horní Bár
Horní Ňáražd
Horní Štál
Hornia Potôň
Horný Bar
Horný Ňáražd
Horný Štál
Jastrabie Korčany
Kerť na Ostrove
Kľučiarove Korčany
Kostolná Gala
Kostolné Korčany
Kráľovicove Korčany
Kulcsod
Kyncelove Korčany
Lesné Korčany
Lidér – Tejed
Lídér Tejed
Mad
Malá Budafa
Malá Lúč
Malé Dvorníky
Malý Aboň
Medve
Moravské Korčany
Nekyje na Ostrove
Ollé – Tejed
Orechová Potôň
Padány
Pataš
Pinkove Korčany
Pódafa
Pósfa
Stará Gala
Süly
Svätý Michal
Szap
Szent Maihályfa
Töböréte
Tökés
Töne
Tône
Trhová Hradská
Trstená na Ostrove
Várhaň
Várkony
Veľká Budafa
Veľká Lúč
Veľké Dvoríky
Veľké Dvorníky
Veľký Aboň
Vieska
-
Feledince
Almáď
Bátka
Belín
Blhovce
Bottovo
Cakov
Číz
Čoma
Darňa
Détér
Dobfenek
Dražice
Dubovec
Dulovo
Dúžava
Feledince
Gemerček
Gortva
Hajnáčka
Harmac
HlavnáJánošovce
Hodejov
Hodejovec
Hostice
Husiná
Chanava
Ivanice
Jánošovce
Jéne
Jestice
Korlát
Kostolná Bašta
Linhartovce
Majom
Martinová
Nižný Blh
Pavlovce
Petrovce
PusztaPavlovce
Radnovce
Rimavská Seč
Rokytník
Slávikovo
Söreg
Stará Bašta
Studená
Sútor
Šíd
Šimonovce
Širkovce
Tajty
TemetöJánošovce
Tomášovce
Uhorské Zahorany
Uzovská Panita
Večeklov
Veľkyňa
Vieska nad Blhom
Vyšný Blh
Zádor
Žíp
-
Galanta
Abrahám
Bél Nemecký
Brakoň
Čierne Nekyje
Čierné Nekyje
Dolná Streda nad Váhom
Dolné Saliby
Dolnia Streda nad Váhom
Dolnie Saliby
Galanta
Gáň
Gest
Hasvár
Hegy
Hody
Horné Saliby
Hornie Saliby
Hrubá Borša
Hrubý Šúr
Janovce
Jazerný Ňáražd
Jezerný Ňáražd
Kajal
Košúty
Kráľov Brod
Kráľová
Krmeš
Maďarský Bél
Malý Diosek
Malý Mačád
Malý Máčad
Malý Šúr
Matka Božia
Mostová Kerť
Nádszeg
Nebojsa
Nemecký Bél
Nová Ves pri Dunaji
Páld
Pustý Fedýmeš
Réca
Senec
Sered
Šáp
Štefanikov
Takšoň
Tallós
Tureň
Váhovce
Veľký Diosek
Veľký Fedýmeš
Veľký Fodýmeš
Veľký Mačád
Veľký Máčad
Vizkelet
Vozokany
Zonc
-
Gelnica
Baracken
Gelnica
Helcmanovce
Hrišovce
Jaklovce
Kaľava
Kluknava
Kojšov
Krompachy
Landstrasse
Legre
Malý Folkmar
Margecany
Mníšek nad Hnilcom
Nižné Slovinky
Nižnie Slovinky
Nižný Medzev
Opátka
Prakovce
Robertová
Robertová ul.
Rolova Huta
Rychnava
Silnica
Smolnická Huta
Smolnícka Huta
Smolník
Spišská Opátka
Stará Voda
Švedlár
Úhorná
Veľký Folkmar
Vyšné Slovinky
Vyšnie Slovinky
Žakarovce
-
Giraltovce
Babie
Benedikovce
Brezno
Brezov
Bukovce
Bystré
Čelovce
Čeľovce
Dubinné
Dukovce
Ďurďoš
Fijaš
Giraltovce
Hankovce
Hanušovce nad Topľom
Hanušovce nad Topľou
Harhaj
Hermanovce
Chmeľov
Kalnište
Kecerovské Pavlovce
Kobylnice
Kochanovce
Koprivnica
Kožany
Kračúnovce
Kručov
Kučín
Kuková
Kurima
Kuzima
Laňov
Lascov
Lopuchov
Lúčka
Lužany
Marhaň
Maťaška
Matovce
Megaš
Megeš
Mičakovce
Nadvej
Nemcovce
Okruhlé
Okrúhle
Oľšavce
Pavlovce
Petrovce
Poliakovce
Porubka
Porúbka
Proč
Prosačov
Pušovce
Pvoč
Radoma
Radvanovce
Remeniny
Ruská Voľa
Ruský Kručov
Soboš
Stulany
Stuľany
Šapinec
Šapínec
Štavnik
Šťavník
Štefurov
Valkovce
Vavrinec
Vlača
Železník
Želmanovce
-
Hlohovec
Alekšince
Ardanovce
Bereksek
Bojničky
Bučany
Dolné Vašardice
Dolné Zelenice
Dolnie Otrokovce
Dolnie Vašardice
Dolnie Zelenice
Dvorníky
Fornosek
Hlohovec
Horné Otrokovce
Horné Vašardice
Horné Zelenice
Hornie Otrokovce
Hornie Vašardice
Hornie Zelenice
Jalšové
Kľačany
Koplotovce
Leopoldov
Lukáčovce
Madunice
Malý Báb
Malženice
Merašice
Mestečko
Orešany
Pastuchov
Posádka
Pustá Kerť
Ratkovce
Rišňovce
Rumanová
Siladice
Svätý Peter
Svrbice
Šág
Šalgočka
Šalgovce
Tekolďany
Tekoľďany
Trakovice
Veľký Báb
Verešvár
Zemianska Kerť
Žlkovce
-
Humenné
Adidovce
Baškovce
Brekov
Brestov
Černina
Dedačov
Gruzovce
Grúzovce
Handrix
Hankovce
Hažín
Hudcovce
Humenné
Humenský Rokytov
Chlumec
Jabloň
Jankovce
Jasenov
Kamenica nad Cirochou
Kamienka
Karná
Kochanovce
Koškovce
Kožkovce
Kudlovce
Kudlovec
Lackovce
Lieskovec
Ľubiša
Lukačovce
Maškovce
Modra
Myslina
Nižné Ladičkovce
Ohradzany
Porubka
Porúbka
Ptičie
Rovné
Slovenská Volová
Slovenské Krivé
Sopkovce
Topoľovka
Turcovce
Udavské
Velopolie
Veľopolie
Vyšné Ladičkovce
Vyšny Hrušov
Vyšný Hrušov
Závadka
Zbudské Dlhé
Zbudský Rokytov
-
Ilava
Beluša
Briestené
Dolná Poruba
Dolní Lieskov
Dolný Lieskov
Dubnica nad Váhom
Ďurďové
Hloža
Horná Poruba
Horní Lieskov
Horný Lieskov
Ilava
Ilávka
Iliavka
Klobušice
Kopec
Košeca
Košecké Rovné
Košecké veľké podhradie
Ladce
Ľadce
Lieskovec
Malé Košecké Podhradie
Malý Kolačín
Mojtín
Podhorie
Podskalie
Prejta
Pružina
Slopná
Trstie
Tunežice
Veľké Košecké Podhradie
Veľký Kolačín
Visolaje
Zliechov
-
Kežmarok
Bušovce
Farkašovce
Folvarky
Hodermark
Holumnica
Huncovce
Javorina
Jurské
Kežmarok
Krig
Kríg
Krížova Ves
Krížová Ves
Lendak
Lendák
Ľubica
Majerka
Maldur
Maldúr
Malý Slavkov
Rakúsy
Ruskinovce
Slovenská Ves
Spišská Belá
Stará Lesná
Strážky nad Popradom
Toporec
Tvarožná
Veľká Lomnica
Vrbov
Výborná
Žakovce
Ždiar
-
Komárno
Akátova 1
Apáca – Szakállas
Boďa
Citronová
Číčov
Dolní Gellér
Dolný Gellér
Ekeč
Ekel
Fiš
Fíš
Guta
Hodžovo
Horný Gellér
Ižap
Jesenná
Kamoča
Keszegfalva
Klížska Nemá
Komárno
Lak
Lodňa
Lodnícka
Mederč
Nová Stráž
Silaš
Szilas
Tôň
Turi – Szakállas
Turi Szakállas
Úzka
Veľké Kosihy
Veľký Meder
Vozová
Zemianska Olča
Zemianská Olča
Zemné
Zlatná na Ostrove
-
Košice
Bačkovík
Barca
Baška
Belža
Beňakovce
Bernátovce
Bidovce
Bočar
Bohdanovce
Boliarov
Bologd
Bubnová
Budimer
Budimír
Bukovec
Bunetice
Buzice
Buzinka
Byster
cigánska kolonia
Čakanovce
Čaňa
Čižatice
Ďurďošík
Ďurkov
Geča
Gyňov
Gýňov
Haniska
Herľany
Hodkovce
Hrašovík
Hýľov
Chrastné
Jiskrova
Kalša
Kalvárská
Kavečany
Kecerovské Kostolany
Kecerovské Peklany
Kecerovské Pekľany
Kecerovský Lipovec
Kehnec
Klečenov
Kokšov – Bakša
Kostolany nad Hornádom
Košice
Košická Belá
Košická Nová Ves
Košické Hámry
Košťany
Kralovce
Kráľovce
Krásna nad Hornádom
Kysak
Lodina Malá
Lodina Veľká
Lorinčik
Lorinčík
Malá Ida
Malá Lodina
Malá Lodiná
Malá Vieska
Migléc
Mudrovce
Myslava
Mysľava
Nádosť
Nádošť
NemeckáVyšná Myšľa
Nižná Hutka
Nižná Kamenica
Nižná Mysľa
Nižná Myšľa
Nižnia Hutka
Nižnia Myšľa
Nižný Čaj
Nižný Olčvár
Nižný Tejkeš
Nižný Večvár
Nové Mesto
Nové Mesto pri Slanci
Nový Salaš
Olivár Vyšný
Olšoviany
Oľšoviany
Opátska
Opátske
Opina
Opiná
Pištelná
Ploské
Polianka
Poľná
Poľov
Ptáčkovce
Rákoš
Rankovce
Rozhanovce
Ruskov
Ružin
Ružín
Rybárska
Seňa
Skároš
Slančík
Slanec
Slanská Huta
Sokoľ
Sokoľany
Svinica
Šaca
Šemša
Šrobárová
Ťahanovce
Tepličany
Tordášyho
Trebejov
Tršťany
Vajkovce
Veľká Ida
Veľká Lodina
Vnútorný Červený breh
Všech Svätých
Všechsvätých
Vyšná Hutka
Vyšná Kamenica
Vyšná Mysľa
Vyšná Myšľa
Vyšné Opátske
Vyšné Opátské
Vyšnia Hutka
Vyšnia Myšľa
Vyšný Čaj
Vyšný Olčvár
Vyšný Tejkeš
Zdoba
Ždaňa
Žebeš
Žírovce
-
Kráľovský Chlmec
Ašvaň
Bačka
Bieľ
Bodrogszög
Boľ
Borša
Boťany
Černá
Černochov
Čop
Dobrá
Kapoňa
Kráľovský Chlmec
Ladmovce
Leles
Malá Bara
Malé Rátovce
Malý Gýreš
Malý Kevežd
Malý Tarkan
Malý Újlak
Pavlovo
Perbeník
Poľany
Rad
Seleška
Solnička
Somotor
Stražné
Strážné
Streda nad Bodrokom
Surty
Svätá Mária
Szentes
Szinyér
Šalamúnová
Téglás
Vécs
Véke
Veľká Bara
Veľké Rátovce
Veľký Gýreš
Veľký Kevežd
Veľký Tarkan
Zemplín
Zétény
-
Kremnica
Bartošova Lehota
Bartošova Lehotka
Blaufuss
Dolná Trnávka
Dolnia Trnávka
Dúbrava
Horná Ves
Horné Opatovce
Hornie Opatovce
Ihráč
Jalná
Janova Lehota
Jastrabá
Kľačany
Kopernica
Kosorín
Kremnica
Kunešov
Ladomer
Lovča
Lovčica
Lúčky
Lutila
Nevoľné
Nová Lehota
Piargy
Pitelová
Slaská
Stará Kremnička
Svätý Kríž nad Hronom
Šášovské Podhradie
Šašovské Pohradie
Šváb
Trnavá Hora
Trubín
Vieska
-
Krupina
Bačovce
Báčovce
Bzovík
Cerovo
Čabradský Vrbovok
Čekovce
Demandice
Devičie
Dolné Mladonice
Dolné Rykynčice
Dolné Semerovce
Dolné Šipice
Dolné Terany
Dolné Turovce
Dolnie Rykynčice
Dolnie Šipice
Dolný Badín
Dolný Dačov Lom
Dolný Turovec
Domaníky
Drášovce
Drážovce
Drienovo
Dudince
Dvorníky
Fedýmeš
Hidvég
Hokovce
Hontianske Tesáry
Horné Mladonice
Horné Rykynčice
Horné Semerovce
Horné Šipice
Horné Terany
Horné Turovce
Hornie Mladonice
Horný Badín
Horný Dačov Lom
Horný Turovec
Hrkovce
Hrušov
Chorvatice
Inám
Jalšovík
Jalšovník
Kleňany
Kostolné Moravce
Kozí Vrbovok
Královce
Kráľovce
Krnišov
Krupina
Lackov
Ladzany
Lišov
Litava
Maďarovce
Medovarce
Merovce
Nekyje nad Ipľom
Nemce
Opatové Moravce
Opátove Moravce
Plášťovce
Preseľany
Santov
Sazdice
Sebechleby
Sečianky
Selce
Senohrad
Sitnianska Lehôtka
Slatina
Stredné Turovce
Stredné Túrovce
Sudince
Sudovce
Súdovce
Sucháň
Šahy
Tešmag
Tešmák
Tompa
Trpín
Uňatín
Veľká Ves nad Ipľom
Vyškovce
Zemiansky Vrbovok
Zemianský Vrbovok
Žibritov
-
Kysucké Nové Mesto
Brodno
Budatínska Lehota
Dolný Vadičov
Dunajov
Horný Vadičov
Klubina
Kotrčiná Lúčka
Krásno nad Kysucou
Krásno nad Kysucov
Kysucké Nové Mesto
Kysucký Lieskovec
Lieskovec
Lieskovec nad Kysucou
Lodno
Lutiše
Malá Rudina
Nesluša
Nová Bystrica
Ochodnica
Oškerda
Pažite
Povina
Radola
Radôstka
Riečnica
Rudina
Rudina a Rudinka
Rudinská
Snežnica
Stará Bystrica
Vadičov Dolný
Vadičov Horný
Veľká Rudina
Vranie
Zabudnie
Zádubnie
Zborov nad Bystricou
-
Levice
Balvany
Bátovce
Bohunice
Bory
Čajkov
Čankov
Dolná Seč
Dolné Brhlovce
Dolné Žemberovce
Dolní Prandorf
Dolnia Seč
Dolnie Brhlovce
Dolnie Žemberovce
Dolný Almáš
Dolný Prandorf
Domadice
Drženice
Horná Seč
Horné Brhlovce
Horné Žemberovce
Horní Pandorf
Hornia Seč
Hornie Brhlovce
Hornie Žemberovce
Horný Almáš
Horný Prandorf
Hronské Kosihy
Hurša
Jalakšová
Kálna
Kálnica
Kľačany
Levice
Lok
Ludany Mýtne
Malé Kozmálovce
Malé Krškany
Malý Kiar
Marušová
Mýtné Ludany
Naďod
Nadošany
Nový Tekov
Opatová
Ovárky
Pečenice
Podlužany
Pukanec
Rybník
Santov
Starý Tekov
Tekovská Nová Ves
Tlmače
Varšany
Veľké Kozmálovce
Veľké Krškany
-
Levoča
Abrahamovce
Baldovce
Beharovce
Behárovce
Bijacovce
Brutovce
Buglovce
Doľany
Domanovce
Dravce
Dúbrava
Dvorce
Dvorec
Granč-Petrovce
Harakovce
Harhov
Harkov
Hradisko
Iliašovce
Jablonov
Janovce
Katúň
Kolbachy
Kolčov
Kurimiany
Lengvarty
Levoča
Lúčka
Machalovce
Nemešany
Nižné Repaše
Olšavica
Oľšavica
Ordzoviany
Pavlany
Pavľany
Poľanovce
Pongracovce
Pongrácovce
Spišská Kapitula
Spišské Podhradie
Spišský Štvrtok
Torysky
Uloža
Vlkovce
Vyšné Repaše
Vyšný Slavkov
Závada
-
Liptovský Svätý Mikuláš
Beharovce
Beňadiková
Benice
Beňušovce
Bobrovček
Bobrovec
Bobrovník
Bodice
Bukovina
Čemice
Dehtary
Dechtare
Demänová
Dlhá Lúka
Dovalovo
Dúbrava
Dúbravka
Gôtoväny
Huby
Huty
Húty
Hybe
Iľanovo
Ilianovo
Ižipovce
Jakubovany
Jakuboväny
Jalovec
Jamník
Klačany
Kľačany
Kokava
Konská
Kráľová Lehota
Kvačany
Lazisko
Liptovská Kokava
Liptovská Teplička
Liptovské Matiašovce
Liptovské Vlachy
Liptovský Hrádok
Liptovský Sv. Ján
Liptovský Svätý Ján
Liptovský Svätý Mikuláš
Liptovský Trnovec
Lubela
Malatíny
Malé Borové
Malé Borovô
Malužiná
Nemecká Ľupča
Nižná Boca
Novoť
Okoličné
Ondrašová
Ondrášová
Paludza
Palúdzka
Parižovce
Parížovce
Pavčina Lehota
Pavlova Ves
Ploštín
Podtureň
Porúbka
Pribylina
Prosiek
Ráztoky
Sielnica
Smrečany
Sokolče
Spišské Vlachy
Svätá Anna
Svätá Mara
Svätá Maria
Svätý Kríž
Svätý Ondrej
Svätý Peter
Štrba
Tomovec
Trnovec
Trstená
Trstené
Uhorská Ves
Ukovská Ves
Vavrišovo
Važec
Veľké Borové
Veľké Borovô
Veterná Poruba
Vlachy
Východná
Vyšná Boca
Zavažná Poruba
Zavážna Poruba
Závažna Poruba
Žiar
-
Lovinobaňa
Cinobaňa
Podkriváň
Podrečany
-
Lučenec
Abelová
Béna
Biskupice
Boľkovce
Breznička
Budiná
Bulhary
Bystrička
Cinobaňa
Čakanovce
Divín
Dobroč
Dravce Panitské
Fiľakovo
Filakovské Kľačany
Fiľakovské Kľačany
Filakovské Kováče
Fiľakovské Kováče
Galoň
Galša
Gregorova Vieska
Halič
Hrabovo
Hradište
Jelšovec
Kalinovo
Kalonda
Kerestúry
Kotmanová
Krná
Lehôtka
Lentvora
Lovinobaňa
Lučenec
Lupoč
Madačka
Malinec
Málinec
Mašková
Mikušovce
Mladzovo
Mládzovo
Mlynská osada
Mučín
Muladka
Muľadka
Mýtna
Nedelište
Nitra
Opatová
Ozdín
Panitské Dravce
Píla
Pinciná
Pleš
Podkriváň
Podrečany
Polichno
Praha
Prša
Raďovce
Rapovce
Rovňany
Ružiná
Stará Halič
Šávoľ
Šuľa
Terbelovce
Terbeľovce
Točnica
Tomášovce
Trenč
Tuhár
Turičky
Turíčky
Uderiná
Uhorské
Veliká nad Ipľom
Veľká Ves
Veľké Dravce
Vidiná
Zelené
-
Malacky
Bikove Humence
Bílkove Humence
Borský Svätý Jur
Borský Svätý Mikuláš
Borský Svätý Peter
Dimburk
Gajary
Hasprunka
Jablonová
Jablonové
Jakubov
Kiripolec
Kripolec
Kuchyňa
Kuklov
Láb
Lakšánksa Nová Ves
Lakšárska Nová Ves
Lozorno
Malacky
Malé Leváre
Moravský Svätý Ján
Niklašov
Pernek
Plavecké Podhradie
Plavecký Svätý Mikuláš
Plavecký Svätý Peter
Plavecký Štvrtok
Rarbok
Sekule
Sološnica
Šajdik Humence
Šajdikove Humence
Uhorská Ves
Veľké Leváre
Závod
-
Medzilaborce
Borov
Brestov
Bystrá
Čabalovce
Čertižné
Habura
Havaj
Hrabovec
Hrubov
Kalinov
Krásny Brod
Krivá Oľka
Makovce
Malá Driečna
Malá Poľana
Malé Staškovce
Medzilaborce
Miková
Ňagov
Nižná Oľka
Nižná Radvaň
Nižné Čabiny
Nižné Zbojné
Oľšinkov
Palota
Pravrovce
Prituľany
Repejov
Rokytovce
Roškovce
Rožkovce
Ruská Kajňa
Ruská Poruba
Sukov
Varechovce
Veľká Driečna
Veľké Staškovce
Világy
Vladiča Nižná
Vladiča Vyšná
Volica
Vydraň
Výrava
Vyšná Oľka
Vyšná Radvaň
Vyšná Vladiča
Vyšné Čabiny
Vyšné Zbojné
Vyšnie Čabiny
Vyšnie Zbojné
Závada
Zbudská Bela
Zbudská Belá
-
Michalovce
AndrássyhoMichalovce
Bánovce nad Ondavou
Bracovce
Budkovce
Čečechov
ČollákovaMichalovce
Drahňov
Dúbravka
Falkušovce
Fišar
Hatalov
Hažín
Hlavná
HlavnáBudkovce
HlavnáDrahňov
HumenskáMichalovce
Iňačovce
Jastrabie
Kačanov
Kaluža
Kopčany
Krásnovce
Krášok
Krivošťany
Kucany
Lastomír
Laškovce
Lesné
Ložín
Lúčky
Malčice
Malé Raškovce
Malé Zalužice
Markovce
MasarykovaMichalovce
Michalovce
Močarany
Moraviany
Nacina Ves
Nad Laborcom
Nižný Hrušov
Oborín
Oreské
Pavlovce nad Uhom
Petrikovce
Petrovce
Pozdišovce
Pusté Čemerné
Rakovec nad Ondavou
Rebrín
Slavkovce
Sliepkovce
Staré
Strážske
Suché
Šamudovce
Tarnava
Topoľany
Trhovište
Veľké Raškovce
Veľké Zalužice
Vinná
Voľa
Vrbovec
Za hradkomMichalovce
Zbudza
Žbince
-
Modra
Báhoň
Cajka
Cajla
Častá
Čataj
Dlhá
Dubova
Dubová
Grinava
Hliník
Hliník Limbach
Igram
Igrám
Jablonec
Kaplna
Kaplná
Kučišdorf
Kučiždorf
Limbach
Limbach – Hliník
Malé Šenkvice
Modra
Modra – Kráľová
Nem. Grób
Nemecký Grob
Ompitál
Pezinok
Píla
Pudmerice
Slovenský Grob
Šarfia
Štefanova
Štefanová
Švajnsbach
Trlinok
Veľké Šenkvice
Vištuk
-
Modrý Kameň
Balog
Bátorová
Brusník
Bušince
Čebovce
Čeláry
Čelovce
Dolná Strehová
Dolná Strechová
Dolné Plachtince
Dolné Príbelce
Dolné Strháry
Dolní Tisovník
Dolnie Plachtince
Dolný Tisovník
Ďurkovce
Glabošovce
Horná Strehová
Horné Plachtince
Horné Príbelce
Horné Strháre
Hornie Príbelce
Horný Tisovník
Chrastince
Chrťany
Kamenné Kosihy
Kamenné Kosy
Kesihovce
Kiarov
Kiazov
Koláry
Kosihovce
Kosihy nad Ipľom
Kosihy nad Ipľou
Kováčovce
Lesenice
Lešť
Ľuboreč
Ľuboriečka
Malá Čalomija
Malé Straciny
Malé Zlievce
Malý Krtíš
Malý Krtýš
Modrý Kameň
Nenince
Nová Ves
Obeckov
Olováry
Opatová Nová Ves
Opatovce – Nová Ves
Opava
Polná Strechová
Pôtor
Pravica
Príboj
Rárošská Muľaď
Rárožská Mulaď
Selany
Selce
Senné
Sennô
Sklabiná
Slovenské Ďarmoty
Slovenské Kľačany
Stará Huta
Stredné Plachtince
Suché Brezovo
Širakov
Širákov
Šuľa
Trebušovce
Turie Pole
Veľká Čalomija
Veľké Lom
Veľké Straciny
Veľké Zlievce
Veľký Krtíš
Veľký Lom
Veľký Lôm
Vereš
Vieska
Vrbovka
Záhorce
Závada
Zombor
Želovce
Žihľava
Žíhľava
-
Moldava nad Bodvou
Bodolov
Buzita
Cestice
Čečejovce
Debraď
Dvorníky
Hačava
Háj
Him
Horváty
Hrhov
Hrušov
Jablonca
Jablonov nad Turnou
Jablonov nad Turnov
Jánok
Jasov
Jasovský Podzámok
Komárovce
Mihyska
Mokrance
Moldava nad Bodvou
Nižný Lánc
Nižný Medzev
Nováčany
Opátka
Paňovce
Péder
Perín
Poproč
Rešta
Rudník
Šomody
Štos
Štós
Turna nad Bodvou
Turnianská Nová Ves
Vendégi
Vyšný Lánc
Vyšný Medzev
Zádiel
Zlatá Idka
Žarnov
-
Myjava
Brezová pod Bradlom
Bukovec
Hrachovište
Kostolné
Košariská – Priepasné
Krajné
Myjava
Podkylava
Turá Lúka
Vaďovce
Višňové
-
Námestovo
Babín
Benadovo
Bobrov
Bobrovo
Breza
Erdudka
Erdúdka
Erdútka
Hruštín
Jasenica
Klin
Krušetnica
Lokca
Lomná
Mutné
Námestovo
Novoť
Polhora
Rabča
Rabčice
Sihelné
Slanica
Tabčice
Ťapešovo
Vaňovka
Vasiľov
Vavrečka
Veselé
Zákamenné
Zubrohlava
-
Nitra
Andač
Ašakerť
Bádice
Behynce
Biskupová
Branč
Bzince
Cabaj-Čápor
Coborika
Čab
Čakajovce
Čalad
Čechynce
Čermany
Dolné Krškany
Dolné Lefantovce
Dolné Obdokovce
Dolné Štitáry
Dražovce
Engelova 6
Gesť
Horné Krškany
Horné Lefantovce
Hrnčiarovce
Ireg
Ivánka pri Nitre
Jagersek
Krtovce
Kynek
Lajšová
Lapašské Ďarmoty
Lehota
Malé Ripňany
Malý Cetín
Malý Lapáš
Mechenice
Močenok
Molnoš
Nitra
Nitra – Zobor
Paňa
Pogranice
Radošiná
Salakúz
Salakúzy
Sila
Sulany
Šalgov
Šarfia
Šarluhy
Šarlužky – Kajsa
Šuránky
Tormoš
Ujlaček
Ujlak
Urmín
Veľké Janíkovce
Veľké Ripňany
Veľký Cetín
Veľký Lapáš
Vozokany
Výčapky
Výčapy – Opatovce
Výčapy-Opatovce
Zbehy
-
Nová Baňa
Brehy
Bukovina
Bzenica
Dolná Ždáňa
Dolné Hámry
Dolnia Ždaňa
Dolnia Ždáňa
Dolnie Hámry
Hlinik nad Hronom
Hliník nad Hronom
Horné Hamry
Horné Hámry
Hornia Trnávka
Hornia Ždáňa
Hornie Hámry
Hrabicov
Hrabičov
Huta – Žarnovická
Huta Žarnovická
Hvozdnica
Hvoznica
Klak
Kľak
Kohútov
Lehotka po Brehy
Lehotka pod Brehy
Malá Lehota
Nová Baňa
Orovnica
Píla
Píla pri stanici Rudno 487
Prestavlky
Pri stanici na Rudne
Pri stanici Rudno
Prochot
Psary
Psáry
Repište
Revištské Podzámčie
Rudno nad Hronom
Sklené Teplice
Slov
Sv. Benadik
Sv. Beńadik
Sv. Beňadik
Sv. Benedik
Sv.Beňadik
Svätý Benadik
Svätý Benedik
Takšoň
Tekovská Breznica
Tekovská Nová Ves
Veľká Lehota
Velké Pole
Veľké Pole
Vyhne
Žarnovica
Župkov
-
Nové Mesto nad Váhom
Bašovce
Beckov
Beckovská Vieska
Brunovce
Čachtice
Častkovce
Dolné Bzince
Dolné Srnie
Horná Streda nad Váhom
Horné Bzince
Hôrka
Hrádok
Hrušové
Kálnica
Kočovce
Korytné
Lubina
Lúka nad Váhom
Mnešice
Modrová
Modrovka
Moravské Lieskové
Mošovce nad Váhom
Nová Lehota
Nová Ves nad Váhom
Nové Mesto nad Váhom
Očkov
Pobedim
Pobedím
Podolie
Potvorice
Rakoľuby
Stará Lehota
Stará Turá
Svätý Kríž nad Váhom
Vieska nad Váhom
-
Nové Zámky
Andód
Bánovská Kesa
Černík
Dolní Síleš
Dolný Síleš
Ďorok
Fedýmeš nad Žitavou
Horný Síleš
Izdeg
Komjatice
Kostolný Sek
Malá Kesa
Malá Maňa
Malá Máňa
Malý Kýr
Malý Várad
Mlynský Sek
Nové Zámky
Slovenský Meder
Svätý Michal
Svätý Michal nad Žitavou
Šurany
Tardošked
Veľký Kýr
-
Parkan
Bajtava
Bart
Bátorové Kesy
Belá
Bíňa
Búcs
Búč
Ďarmotky
Diva
Ebed
Farnád
Helenba
Kamendín
Kamenica nad Hronom
Kamenné Ďarmoty
Karva
Keť
Kičind
Köbölkút
Kuralany
Leléd
Libád
Malé Kosihy
Moča
Mužla
Nána
Nová Vieska
Páld
Parkan
Salka
Seldín
Veľké Ludince
-
Parkan – Štúrovo
Bajtava
Bart
Bátorove Kesy
Belá
Bíňa
Búč
Ďarmotky
Diva
Ebed
Farnád
Helemba
Kamendín
Kamenica nad Hronom
Kamenné Ďarmoty
Karva
Keť
Kičind
Köbölkút
Kuralany
Leléd
Libád
Malé Kosihy
Moča
Mužla
Nána
Nová Vieska
Páld
Parkan
Salka
Seldín
Šarkan
ŠimorováParkan
TulipánovaKarva
Veľké Ludince
-
Piešťany
Banka
Borovce
Dobrá Voda
Dolné Dubovany
Dolný Lopašov
Domky na farárovej role
Drahovce
Ducové
Horné Dubovany
Hubina
Hviezdoslavova
Chtelnica
Kocurice
Kočín
Krakovany
Lančár
Malé Orvište
Moravany nad Váhom
Nižná
Nová Piešťany
Objekt nádražia
Ostrov
Pečeňady
Piešťany
PolnáPiešťany
Rakovice
Ratnovce
Sládkovičová
Slepá z nádražnej
Sokolovce
Stráže
Stráže nad Váhom
Šafariková
Šípkové
Šterusy
Ťapkové
Trebatice
Veľké Kostolany
Veľké Orvište
Veselé
Vrbové
Vrbovska cesta
Weinbergerova tehelňa
Zákostolany
-
Poprad
Batizovce
Gánovce
Gerlachov
Horka
Hozelec
Hranovnica
Kraviany
Kubachy
Lučivná
Matejovce
Mengušovce
Milbach
Nižná Šuňava
Nová Lesná
Poprad
Spišská Sobota
Spišská Teplica
Stráža
Štavník
Šťavník
Štôla
Švábovce
Veľká
Veľký Slavkov
Vernár
Vikartovce
Vyšná Šuňava
-
Považská Bystrica
Bodiná
Brvnište
Dolný Moštenec
Domaniža
Drienové
Hatné
Horná Maríková
Horný Moštenec
Jesenica
Klieština
Kardošova Vieska
Kostelec
Kvašov Zemiansky
Lednice Malé
Lehota Čelková
Malá Udiča
Malé Lednice
Mariková
Maríková
Milochov
Orlové
Papradno
Plevník
Počarová
Podmanín
Podvažie
Považská Bystrica
Považská Teplá
Považské Podhradie
Praznov
Prečin
Prečín
Prosné
Sadečné
Stupné
Sverepec
Šebešťanová
Upohlav
Veľká Udiča
Vrchteplá
Vrtižer
Záskalie
Zemianska Závada
Zemiansky Kvašov
-
Prešov
Abranovce
Bajerov
Bogdanovce
Brestov
Bretejovce
Bujakov
Bzenov
Červenica
Demjata
Drienov
Drienovská Nová Ves
Fintice
Fričovce
Fulanka
Fuľanka
Guľvas
Haniska
Haršag
Hažgut
Hrabkov
Huviz
Chabžany
Chmeľovec
Chmiňany
Chminianska Nová Ves
Chminianská Nová Ves
Janov
Janovík
Kapušany
Kelemeš
Kendice
Kereštvej
Klembarok
Kojatice
Kojetice
Kokošovce
Kokyňa
Košická 56
Kovárna
Križoviany
Kuchyňa
Kvačany
Lačnov
Lada
Lažany
Lemešany
Lesíček
Ličartovce
Lipovce
Lipovec
Ľubovec
Lužánky
Malý Daniš
Malý Šariš
Meretice
Miklušovce
Mikušovce
Močarmany
Mojzesová
Mojzesova 1046
Nemcovce
Nemecké Jakubovany
Nemecké Jakuboviany
Nižná Šebestová
Nižné Mirkovce
Nižný Sebeš
Nižný Šebeš
Obyšovce
Ondrašovce
Ovčie
Petroviany
Podhradík
Prešov
Radačov
Rokycany
Ruská Nová Ves
Ruské Pekľany
Sedikart
Sedlice
Seňakovce
Sladkovičova
Solivar
Solná Baňa
Soľná Baňa
Suchá Dolina
Svinia
Šalgovík
Šalgovník
Šariš
Šarišské Lúky
Šinglar
Široké
Šváby
Terjakovce
Tuhrina
Tulčík
Vagaš
Varhanovce
Varhaňovce
Veľký Šariš
Vitež
Vyšná Šebestová
Vyšné Mirkovce
Vyšný Šebeš
Zlatá Baňa
Žegňa
Žipov
Župčany
-
Prievidza
Banky
Bojnice
Brezany
Brusno
Bystričany
Cech
Cígeľ
Cígl
Čavoj
Čereňany
Diviacka Nová Ves
Diviaky nad Nitricou
Diviaky nad Nitrou
Dlžín
Dobročná
Dolné Vestenice
Dolný Kamenec
Dubnica
Dvorníky
Dvorníky nad Nitricou
Dvorníky nad Nitrou
Gajdel
Handlová
Harné Lelovce
Horné Lelovce
Horné Vestenice
Horný Kamenec
Hradce
Hradec
Chrenovec
Chvojnica
Jalovce
Jalovec
Ješkova Ves
Ješková Ves
Kanianka
Kocurany
Kostolná Ves
Koš
Laskár
Lazany
Liešťany
Lipník
Lomnica
Mačov
Majzel
Malá Čausa
Malá Lehota
Malá Lihotka
Morovno
Necpaly nad Nitrou
Nedožery
Nemecké Pravno
Nevidzany
Nitrianske Rudno
Nováky
Opatovce nad Nitrou
Oslany
Podhradie
Poluvsie
Poruba
Pravenec
Prievidza
Račice
Raztočno
Ráztočno
Rudnianska Lehota
Sebedražie
Seč
Solka
Sučany
Šutovce
Temeš
Tužina
Valaská Belá
Veľká Čausa
Veľká Lehota
Veľká Lihotka
Vrbäny
Zemianske Kostolany
Zemianské Kostolany
-
Púchov
Bohunice
Bolešov
Borčice
Červený Kameň
Dohňany
Dolná Breznica
Dolné Kočkovce
Dubková
Dulov
Dúlov
Horenice
Horná Breznica
Horovce
Hoštiná
Hôrka
Hrabovka
Ihrište
Kameničany
Krivoklát
Kvašov
Lazy pod Makytou
Lednica
Lednice
Lednická Lehota
Lednické Rovne
Lúky
Lysá pod Makytou
Medné
Mestečko
Mikušovce
Mostiše
Mostište
Nimnica
Nosice
Piechov
Pruské
Púchov
Savčina – Podvažie
Sedmerovce
Sedmerovec
Slavnica
Slávnica
Streženice
Tuchyňa
Vieska – Bezdedov
Vršatské Podhradie
Vydrná
Zarečie
Zariečie
Záriečie
Zbora
Zubák
-
Revúca
Brusník
Filier
Grlica
Hrubá Lehôtka
Hucín
Chyžné
Jelšava
Jelšavcská Teplica
Jelšavská Teplica
Kameňany
Kopráš
Licince
Lienice
Lubeník
Migles
Miglés
Mikolčany
Mníšany
Mokrá Lúka
Muráň
Muránska Dlhá Lúka
Muránska Huta
Muránska Lehota
Muránska Zdychava
Muráňska Zdychava
Nandraž
Nováčany
Ploské
Prihradzany
Rákoš
Ratková
Ratkovská Lehota
Ratkovské Bystré
Repištia
Revúca
Revúčka
Rybník
Sása
Sirk
Šivetice
Španie Pole
Turčok
Umrlá Lehota
-
Rimavská Sobota
Babinec
Babínec
Bakta
Brádno
Budikovany
Čerenčany
České Brezovo
Drábsko
Drienčany
Ďubakovo
Hačava
Hnúšťa
Hostišovce
Hrachovo
Hrnčiarske Zalužany
Hrušovo
Klenovec
Kociha
Kokava nad Rimavicou
Kraskovo
Kyjatice
Lehota Rimavská
Likier
Lipovec
Lom nad Rimavicou
Lukovištia
Malé Teriakovce
Malé Terjakovce
Melecheď
Nižná Pokoradz
Nižný Skalník
Nižný Skálnik
Ostrany
Ožďany
Padarovce
Pápča
Píla
Polom
Poltár
Pondelok
Poproč
Potok
Ratkovská Suchá
Ratkovská Zdychava
Rimavica
Rimavská Baňa
Rimavská Lehota
Rimavská Sobota
Rimavské Brezovo
Rimavské Zalužany
Rimavské Zálužie
Rovné
Rovné Zahorany
Selce
Siartovská
Sihla
Slaná Lehota
Slizké
Slizské
Slovenské Zahorany
Striežovce
Sušany
Šoltýska
Tisovec
Tomášová
Váhom
Vaľkovo
Veľká Suchá
Veľké Teriakovce
Vrbovce
Vrbovec
Vyšná Pokoradz
Vyšny Skalník
Vyšný Skálnik
Zacharovce
-
Rožňava
Betliar
Borka
Borzová
Bôrka
Brdárka
Brezová
Brzotín
Čierna Lehota
Čučma
Dobšina
Dobšiná
Drnava
Gecelovce
Genč
Gočaltovo
Gočovo
Hanková
Hankovce
Hárskút
Henckovce
Imrichovce
Jólész
Kerešovce
Kobeliarovo
Kováčová
Krásnohorská Dlhá Lúka
Krasnohorské Podhradie
Krásnohorské Podhradie
Kunova Teplica
Lúčka
Malá Poloma
Markuška
Nadabula
Nižná Slaná
Ochtina
Ochtiná
Pača
Pašková
Petermánovce
Petrmánovce
Plešivec
Rejdová
Rekeňa
Rochovce
Roštár
Rozložná
Rožňava
Rožňavské Bystré
Rudná
Salovec
Silica
Slavoška
Slavošovce
Sučany
Štefanovce
Štitník
Štítnik
Veľká Poloma
Vidová
Vlachovo
Vyšná Slaná
Ztratená
-
Rožňova Neporadza
Rožňova Neporadza
-
Ružomberok
Bešeňová
Biely Potok
Černová
Gombáš
Hrboltová
Ivachnová
JelenceRužomberok
Kalameny
Komjatná
Likavka
Liptovská Lužna
Liptovská Lužná
Liptovská Lúžna
Liptovská Osada
Liptovská Štiavnica
Liptovská Teplá
Liptovské Revúce
Lisková
Lúčky
Madočanská
Martinček
Námestie
Pivovarská
Polná
Potok
Považská
Ružomberok
Sliače
Stankovany
Štiavnička
Švošov
Turík
Vlašky
Vrbie
Zemianska Ludrová
-
Sabinov
Bajerovce
Balpotok
Bertotovce
Blažov
Bodolak
Brezovica nad Tornaľou
Brezovica nad Torysou
Červenica
Čirč
Ďačov
Daletice
Dubovica
Geralt
Gergelak
Gombošovce
Hamborek
Hanigovce
Hendrichovce
Hermanovce
Hradisko
Jakoviany
Jakubova Voľa
Jakuboviany
Jarovnice
Jastrabie
Kamenica
Kriviany
Kyjov
Lipiany
Ľubotín
Lúčka
Ľutina
Malý Slivník
Medzany
Michaľany nad Torysou
Močidlany
Močidľany
Mošurov
Ňaršany
Nižní Slavkov
Nižný Slavkov
Obručné
Olejníkov
Oľšov
Orkucany
Orlov
Orlov nad Popradom
Ostroviany
Pečovská Nová Ves
Plaveč nad Popradom
Poloma
Ratvaj
Renčišov
Roškoviany
Ruská Voľa
Sabinov
Šarišské Dravce
Šenviz
Šoma
Štefanovce
Štelbach
Terňa
Tolčemeš
Torysa
Ujak
Uzovce
Uzovské Pekľany
Uzovský Šalgov
Veľký Slivník
Vislanka
Vysoká
Závadka
Žatkovce
-
Senica
Cerová-Lieskové
Čáčov
Čáry
Častkov
Dojč
Hlboké
Hradište pod Vrátnom
Jablonica
Kovalov
Kunov
Osuské
Podbranč
Prietrž
Rohov
Rovensko
Rozbehy
Rybky
Senica
Smolinské
Smrdáky
Sobotište
Sotina
Stráže nad Myjavou
Šandorf
Šaštín
Štepanov
Vrbovce
-
Skalica
Brodské
Gbely
Holič
Chropov
Kátov
Kopčany
Kovalovec
Kúty
Letničie
Lopašov
Močidlany
Mokrý Háj
Nočidlany
Oreské
Petrova Ves
Popudiny
Prietržka
Radimov
Radošovce
Ružová ulicaHolič
Skalica
Trnovec
Unin
Unín
Vidovany
Vieska
Vlčkovany
Vrádište
-
Snina
Belá nad Cirochou
Berezovec
Brezovec
Čukalovce
Dara
Dlhá nad Cirochou
Dlhé nad Cirochou
Dúbrava
Hostovice
Hrabová Roztoka
Inovce
Jalová
Kalná Roztoka
Klenová
Kolbasov
Kolonica
Ladomirov
Michajlov
Nechválova Poľanka
Nechválová Poľanka
Nižná Jablonka
Nižnia Jablonka
Nová Sedlica
Ostrožnica
Ostrožnice
Papín
Parihuzovce
Pčoliné
Pichne
Príslop
Runina
Ruská Bystrá
Ruská Volová
Ruské
Ruský Hrabovec
Ruský Potok
Smolník
Snina
Stakčianska Roztoka
Stakčín
Starina
Strihovce
Šmigovce
Šmigovec
Telepovce
Topoľa
Ubľa
Ulič
Uličské Krivé
Valaškovce
Veľká Poľana
Volová
Vyšná Jablonka
Vyšnia Jablonka
Zboj
Zubné
Zvala
-
Sobrance
Baškovce
Bašoľa
Beňatina
Bežovce
Blatná Poľanka
Blatné Remety
Blatné Revištia
Bunkovce
Fekišovce
Gajdoš
Hlivište
Hlivištia
Hnojné
Horňa
Husák
Choňkovce
Jenkovce
Jesenov
Jesnov
Jovsa
Klokočov
Kolibabovce
Komárovce
Koňuš
Koromľa
Krčava
Kristy
Kusín
Malý Gajdoš
Nemecká Poruba
Nemecké Vyšné
Nižná Rybnica
Nižné Nemecké
Orechová
Ostrov
Petrovce
Pinkovce
Podhoroď
Poľanka Blatná
Porostov
Porúbka
Priekopa
Remetské Hámry
Remety Vyšné
Ruskovce
Rybnica Vyšná
Sejkov
Sentuš
Sobrance
Tašoľa
Tibava
Úbrež
Vojnatina
Vyšná Rybnica
Vyšné Nemecké
Vyšné Remety
Vyšné Revište
Vyšné Revištia
Záhor
Závadka
-
Spišská Nová Ves
Arnutovce
Betlanovce
Danišovce
Folvark
Gibeľ
Hágy
Haligovce
Harichovce
Havka
Henclová
Hincovce
Hnilčík
Hrabušice
Chrasť nad Hornádom
Jamník
Jezersko
Kalenberk
Kolínovce
Koterbachy
Krompachy
Lechnica
Lesnica
Letanovce
Lieskoviany
Malá Franková
Markušovce
Matejovce
Matiašovce
Nižné Slovinky
Nižné Šváby
Odarin
Odorin
Odorín
Olcnava
Olenava
Olšavka
Oľšavka
Ostruňa
Osturňa
Ponač
Porač
Slatvina
Smižany
Spišská Nová Ves
Spišská Stará Ves
Spišské Hanušovce
Spišské Tomašovce
Spišské Tomášovce
Spišské Vlachy
Spišský Hrušov
Teplička
Tomašovce
Velbachy
Veľbachy
Veľká Franková
Veľký Lipník
Vitkovce
Vondrišel
Vydrník
Vyšné Slovinky
Závadka
Žehra
-
Spišská Stará Ves
Folvark
Hágy
Haligovce
Havka
Jezersko
Lesnica
Malá Franková
Matiašovce
Nižné Lapše
Nová Belá
Osturňa
Reľov
Rychvald
Spišská Stará Ves
Spišské Hanušovce
Tribš
Veľká Franková
Veľký Lipník
Vyšné Šváby
-
Spiššká Nová Ves
Arnutovce
Beltanovce
Danišovce
Harichovce
Henclová
Hincovce
Hnilčík
Hrabušice
Chrasť nad Hornádom
Jamník
Kolínovce
Koterbachy
Letanovce
Lieskovany
Spišská Nová Ves
Spišský Hrabušov
-
Stará Ďala
Bagota
Bajč
Baromlak
Čecky
Čechy
Čúz
Dvory nad Žitavou
Fyr
Fýr
Hetín
Imeľ
Iža
Járová
Jásová
Kerť
Kolta
Koľta
Krátke Kesy
Madar
Mantoš
Marcelová
Martoš
Mudroňovo
Nasvad
Nesvad
Nová Ďala
Perbete
Radvaň nad Dunajom
Semerovo
Stará Ďala
Sv. Peter
Svätý Peter
Šrobárová
-
Stará Ľubovňa
Forbasy
Gňazda
Gňazdá
Granastov
Gromoš
Hajtovka
Hobgart
Jakubiany
Jarabina
Jarabiná
Kamionka
Kolačkov
Krempach
Lacková
Legnava
Litmanová
Lomnička
Malý Lipník
Malý Sulín
Matysová
Mníšek nad Popradom
Nižné Ružbachy
Nová Ľubovňa
Pilhov
Pílhov
Plavnica
Podolinec
Podolínec
Podsádek
Stará Ľubovňa
Starina
Šambron
Štós
Veľký Sulín
Vyšné Ružbachy
-
Stropkov
Belejovce
Bodružal
Bodružaľ
Bokša
Breznica
Breznička
Brusnica
Bžany
Cernina
Cigla
Černina
Ďapalovce
Dobroslava
Dolhoňa
Dubová
Duplin
Duplín
Giglovce
Girovce
Gribov
Havranec
Holčikovce
Holčíkovce
Hrabovčík
Hunkovce
Chotča
Jakušovce
Jurkova Voľa
Kapišová
Kečkovce
Kelča
Kolbovce
Korejovce
Košarovce
Kožuchovce
Krajná Bystrá
Krajná Poľana
Krajná Porúbka
Krajná-Čarno
Krajné Čarno
Krišlovce
Križľovce
Krušina
Krušinec
Kružlová
Kurimka
Ladomirová
Ladomírová
Lomné
Malá Domaša
Malé Bukovce
Medvedzie
Mergeška
Mestisko
Miňovce
Miroľa
Mlynárovce
Mrázovce
Nižná Jedlová
Nižná Jedľová
Nižná Oľšava
Nižná Pisaná
Nižná Sitnica
Nižnia Oľšava
Nižnia Pisaná
Nižnia Sitnica
Nižný Komárnik
Nižný Mirošov
Nižný Orlík
Nižný Svidník
Oľšavka
Pakostov
Petejovce
Petrovce
Piskorovce
Potočky
Potoky
Príkra
Pstriná
Pucak
Rafajovce
Rakovčík
Rohožník
Rovné
Roztoky
Solník
Stročín
Stropkov
Suchá
Svidnička
Šandál
Šarbov
Šemetkovce
Tisinec
Tokajík
Turiany
Vagrinec
Valkov
Vápeník
Veľká Domaša
Veľké Bukovce
Veľkrop
Vislava
Vojtovce
Vyškovce
Vyšná Jedlová
Vyšná Jedľová
Vyšná Oľšava
Vyšná Pisaná
Vyšná Sitnica
Vyšnia Oľšava
Vyšnia Pisaná
Vyšný Hrabovec
Vyšný Komárnik
Vyšný Mirošov
Vyšný Orlík
Vyšný Svidník
-
Šala
Diakovce
Dlhá nad Váhom
Farkašd
Horná Kráľová
Kepežd
Močenok
Neded
Pered
Selice
Šala
Šók
Šoporňa
Trnovec nad Váhom
Veča
Žigard
-
Šaľa
Deáki
Dlhá nad Váhom
Farkašd
Horná Kráľová
Kepežd
Kráľová nad Váhom
Močenok
Neded
Pata
Pered
Selice
Šaľa
Šintava
Šók
Šoporňa
Trnovec
Trnovec nad Váhom
Veča
Veča nad Váhom
Žigard
-
Šamorín
Bačfa
Béke
Bél – Vata
Biskupice pri Dunaji
Blatná na Ostrove
Bucsuháza
Bústelek
Csenke
Čakany
Čela
Čilistov
Čukarská Paka
Dobrohošť
Dolné Janíky
Eberhart
Fél
Gomba
Gutor
Horné Janíky
Illésháza
Jelka
Komárov
Község
Kráľovianky
Kyselica
Macov
Malá Paka
Malý Lég
Malý Mager
Miloslavov
Mischdorf
Mliečno
Most na Ostrove
Nová Jelka
Olgya
Predná Potôň
Predná Pôtoň
Sása
Schildern
Szemet
Šamorín
Štvrtok na Ostrove
Tartschendorf
Tonkháza
Trnávka
Úzor
Vajas – Vata
Vajka nad Dunajom
Veľká Paka
Veľká Sarva
Veľký Lég
Veľký Mager
Verekne
Vlky
-
Topoľčany
Baštín
Belince
Blesovce
Bojná
Bošany
Broďany
Čeľadince
Dolné Chlebany
Dolnie Chlebany
Dvorany nad Nitrou
Hajná Nová Ves
Horná Ves
Horné Chlebany
Horné Obdokovce
Horné Štitáry
Hornie Chlebany
Hradište
Hrušovany
Chrabrany
Chynorany
Jacovce
Janova Ves
Ješkova Ves
Ješková Ves
Kamanová
Klátova Nová Ves
Klátová Nová Ves
Kliž
Klíž
Kližské Hradište
Klížske Hradište
Kolačno
Kovarce
Krásno
Krnča
Krušovce
Kuzmice
Lipovník
Livina
Livinské Opatovce
Lovasovce
Lovásovce
Ludanice
Malé Bedzany
Malé Bielice
Malé Dvorany
Malé Kršteňany
Malé Uherce
Mýtna Nová Ves
Nadlice
Navojovce
Nedanovce
Nedašovce
Nemčice
Nemečky
Nitrianska Streda
Norovce
Obsolovce
Oponice
Pažiť
Podhradie
Prašice
Praznovce
Práznovce
Preseľany
Radobica
Rajčany
Selčany
Selčianky
Skačany
Súlovce
Šimonovany
Tesáry
Topoľčany
Tovarníky
Turčianky
Tvrdomestice
Urmince
Veľké Bedzany
Veľké Bielice
Veľké Dvorany
Veľké Kršteňany
Veľké Uherce
Velušovce
Závada
Žabokreky nad Nitrou
-
Tornaľa
Abovce
Ardovo
Barca
Behynce
Bretka
Čoltovo
Držkovce
Figa
Gemer
Gemerská Horka
Gemerská Panita
Hosúsovo
Hrkáč
Hubovo
Chvalová
Kečovo
Kesovce
Králik
Lekeňa
Lenka
Lévárt
Levkeška
Mehy
Meliata
Michalovce
Napraď
Nižná Káloša
Nižné Valice
Oldalfalva
Otročok
Polina
Rašice
Riečka
Rumince
Sekeňa
Skerešovo
Starňa
Svätý Kráľ
Šankovce
Štrkovec
Tornaľa
Višňové
Vyšná Káloša
Vyšné Valice
Žiar
-
Trebišov
Bačkov
Baranč
Božčice
Božice
Byšta
Cejkov
Čelovce
Čeľovce
Čergov
Dargov
Dvorianky
Egreš
Garaň
Gerčeľ
Hardište
Horovce
Hriadky
Imbreg
Jastrabie
Kašov
Kerestúr
Kista
Klečenov
Kochanovce
Kolbaš
Kožuchov
Kraviany
Kuzmice
Lastovce
Legiňa
Malá Toroňa
Malé Ozorovce
Malý Kazimír
Malý Ruskov
Miglešov
Michaľany
Nové Mesto
Parchoviany
Plechotice
Rumanová
Sečovce
Silvaš
Sirnek
Slanec
Slovenské Nové Mesto
Stanča
Stankovce
Trebišov
Trnavka
Trnávka
Tušice
Tušická Nová Ves
Uhorský Žipov
Ujlak
Upor
Úpor
Veľaty
Veľká Toroňa
Veľké Ozorovce
Veľký Kazimír
Veľký Ruskov
Višňov
Vojčice
Zbehňov
-
Trenčín
Adamovce – Malé Bierovce
Bošáca
Dobrá
Dolná Súča
Dolné Zariečie
Dolné Záriečie
Drietoma
Haluzice
Hámry
Hanzlíková
Horná Súča
Horné Srnie
Hrabovka
Istebník
Ivanovce
Kľúčové
Kockanovce
Kostolná
Krivosúd- Bodovka
Kubrá
Kubrica
Liborča
Malá Choholná
Malé Bierovce
Malé Stankovce
Melčice
Mníchova Lehota
Mníchová Lehota
Nemšová
Omšenie
Opatová
Opatovce
Orechové
Rozvadze
Sedličná
Selec
Skala
Skalská nová Ves
Soblahov
Štvrtok
Tremčianska Turná
Trenč. Biskupice
Trenčianska Teplá
Trenčianska Turná
Trenčianske Biskupice
Trenčianske Bohuslavice
Trenčianske Teplice
Trenčín
Újezd
Valčice
Veľká Chocholná
Veľké Bierovce
Veľké Stankovce
Záblatie
Zamarovce
Závada
Zemanske Lieskové
Zemanské Podhradie
Zemianské Lieskové
Zemianske Podhradie
Zlatovce
-
Trnava
Biely Kostol
Biksard
Bíňovce
Bohdanovce nad Trnavou
Bohunice
Boleráz
Borová
Cífer
Dehtice
Dechtice
Dolná Krupá
Dolné Dubové
Dolné Lovčice
Dolné Orešany
Dolnie Orešany
Dolný Čepen
Farkašín
Gocnod
Horná Krupá
Horné Dubové
Horné Lovčice
Horné Orešany
Horný Čepen
Hrnčiarovce
Jáslovce
Katlovce
Kátlovce
Kerestúr
Klčovany
Košolná
Lošonec
Majcichov
Malé Brestovany
Mestský HliníkTrnava
Modranka
Nádaš
Naháč
Neštich
Opoj
Pác
Paderovce
Pustý Fedýmeš
Radošovce
Rožindol
Sereď
Slovenská Nová Ves
Smolenice
Stredný Čepen
Suchá nad Parnou
Šelpice
Špačince
Trnava
Valtašúr
Varašúr
Veľké Brestovany
Veľké Šurovce
Veľké Šúrovce
Voderady
Zavar
Zeleneč
Zemianske Šúrovce
Zvončín
-
Trstená
Brezovica
Bukovina – Podsklie
Čimhová
Dolný Štepanov
Habovka
Hámry
Hladovka
Horný Štepanov
Chyžné
Jablonka
Krásna Hôrka
Liesek
Medvedzie
Nižná Lipnica
Nižná nad Oravou
Nižná Zubrica
Oravka
Oravský Biely Potok
Osada
Pekelník
Podbiel
Podvlk
Srnie
Suchá Hora
Trstená
Tvrdošín
Ústie nad Oravou
Vitanová
Vyšná Lipnica
Vyšná Zubrica
Zábidovo
Zemianska Dedina
Zuberec
-
Turčianský sv.Martin
Abramová
Dubové
Turčianska Blatnica
Vrútky
-
Turčiansky Svätý Martin
Abrahamová
Abramová
Belá
Benice
Blažovce
Blážovce
Bodorová
Bodovice
Borcová
Briešťa
Budiš
Bystrička
Čremošné
Črenošné
Daňová
Ďanová
Diaková
Diviaky
Dolná Štubňa
Dolné Jaseno
Dolní Turček
Dolnia Štubňa
Dolnie Jaseno
Dolný Kalník
Dolný Turček
Dražkovce
Dubová
Dubové
Dulice
Dvorec
Folkušová
Hadviga
Háj
Horná Štubňa
Horné Jaseno
Horní Turček
Hornia Štubňa
Hornie Jaseno
Horný Kalník
Horný Turček
Ivančiná
Jasenovo
Jazernica
Kaľamenová
Karlová
Kevice
Klačany
Kľačany
Kláštor pod Znievom
Koňská
Konské
Košťany nad Turcom
Krpeľany
Laclavá
Laskár
Lazany
Ležiachov
Liešne
Liešné
Lipovec
Malý Čepčín
Moškovec
Mošovce
na Strane
na Stráne
Národný domTurčiansky Svätý Martin
Necpaly
Nedozor
Nolčovo
Ondrašová
Podhradie
Podzámok Sklaniňský
Polerieka
Príbovce
Priekopa
Rakov
Rakovo
Rakša
Ratkovo
Rúdno
Sklabina
Sklabiňa
Sklabinský Podzámok
Sklené
Sloväny
Slovenské Pravno
Socovce
Sučany
Sv. Peter
Sváta Mária
Svätá Mara
Svätý Ďur
Svätý Michal
Svätý Peter
Štiavnička
Štubnianske Teplice
Šútovo
Tomčany
Trebostovo
Trnovo
Turany
Turčianska Blatnica
Turčiansky Svätý Martin
Valča
Valentová
Veľký Čepčín
Vieska
Vrícko
Vrútky
Záborie
Záturčie
Zorkovce
Žabokreky
-
Veľká Bytča
Dlhé Pole
Dolné Hlboké
Dolný Hričov
Hliník nad Váhom
Horné Hlboké
Horný Hričov
Hrabová
Hrabové
Hričovské Podhradie
Hvozdnica
Hvozdnice
Jablonové
Kolarovice
Kolárovice
Malá Bytča
Malá Bytča – Mikšová
Maršová
Paština Závada
Peklina
Petrovice
Predmier
Pšurnovice
Setechov
Súľov – Hradná
Štiavnik
Veľká Bytča
Veľká Bytrča
Veľká Kotešová
Veľké Rovné
Zarieč – Keblov
Zemianska Kotešová
Zemianská Kotešová
-
Veľké Kapušany
Bajany
Batva
Beša
Budaháza
Čičarovce
Čierne Pole
Galoč
Ižkovce
Kľačany
Komárovce
Malé Slemence
Maťovce
Močiar
Moďoroš
Mogyorós
Mokča-Krisov
Ňarád
Palaď
Palín
Palov
Pavlovce
Pavlovce nad Uhom
Ptruksa
Ruská
Senné
Stretava
Stretavka
Tegeňa
Vajany
Vajkovce
Veľké Kapušany
Veľké Slemence
Veškovce
Vysoká
-
Vráble
Babindol
Baračka
Beleg
Beša
Bešeňov
Čaka
Čifáry
Ďarmoty nad Žitavou
Dedinka t. Fajkurt
Dekeneš
Dolný Ďúrad
Dolný Ohaj
Dolný Pial
Dyčka
Fíš
Horný Ďúrad
Horný Ohaj
Horný Pial
Hul
Iňa
Jesenské
Kalaz
Lót
Lula
Malé Hyndice
Melek
Mochovce
Nová Ves nad Žitavou
Plavé Vozokany
Pozba
Rendva
Tajná
Tehla
Teldince
Vajka nad Žitavou
Valkáz
Veľká Maňa
Veľké Hyndice
Vráble
-
Vranou nad Topľou
Černé
-
Vranov nad Topľou
Banské
Benkovce
Cabov
Čaklov
Čemerné
Černé
Čičava
Davidov
Detrik
Dobrá nad Ondavou
Hencovce
Hlinné
Jastrabie
Jesenovce
Juskova Voľa
Kamenná Poruba
Kladzany
Kolčovské Dlhé
Komariany
Kučín
Kvakovce
Majerovce
Malá Domaša
Matiašovce
Merník
Michalok
Nižní Hrabovec
Nižný Hrabovec
Petkovce
Poša
Rudlov
Ruský Kazimír
Sačurov
Sečovská Poľanka
Sedliská
Skrabské
Slovenská Kajňa
Slovenský Žiškov
Soľ
Štefanovce
Tovarné
Tovarnianska Poľanka
Trepec
Uhorský Kručov
Vechec
Vranov nad Topľou
Vranovské Dlhé
Zámutov
Zlatník
Žalobín
-
Vyšný Svidník
Ladomirová
Nižný Komárnik
-
Zlaté Moravce
Beladice
Čaradice
Čierne Kľačany
Dolné Slažany
Gýmeš
Gýmešské Kostolany
Horné Slažany
Hostie
Hosťovce
Choča
Chyzerovce
Jedľové Kostolany
Kňažice
Koleňany
Kostolany
Kozárovce
Ladice
Lovce
Machulince
Malé Chrašťany
Malé Vozokany
Mankovce
Mlyňany
Nemce
Nemčiňany
Neverice
Nevidzany
Obyce
Opatovce nad Žitavou
Prílepy
Rohožnica
Skýcov
Slepčany
Svätý Martin
Tesáry nad Žitavou
Topoľčianky
Velčice
Veľké Chrašťany
Veľké Vozokany
Verešvár
Vieska nad Žitavou
Volkovce
Zlaté Moravce
Zlatno
Žikava
Žirany
-
Zvolen
Babiná
Bacúrov
Breziny
Budča
Bzovská Lehôtka
Detva
Detvianska Huta
Dobrá Niva
Dubové
Dúbravy
Hájniky
Hriňová
Hronská Breznica
Klokoč
Kováčová
Kráľová
Krokoč
Lieskovec
Lukové
Michalková
Môťová
Očová
Ostrá Lúka
Pliešovce
Podzámčok
Rybáry
Sampor
Sása
Sielnica
Slatina
Slatinka
Slatinské Lazy
Stožok
Trnie
Tŕnie
Turová
Veľká Lúka
Vígľaš
Víglašská Huta-Kalinka
Vígľašská Huta – Kalinka
Zolná
Zvolen
Zvolenská Slatina
Železná Breznica
-
Želiezovce
Agov
Bajka
Bielovce
Čata
Damaša
Dolní Feďvernek
Dolní Varád
Dolní Várad
Dolný Feďvernek
Hontianske Ďarmoty
Horní Feďvernek
Horní Varád
Horní Várad
Horný Feďvernek
Hulvínky
Lekýr
Lontov
Málaš
Malé Ludince
Malé Šarovce
Malý Pesek
Mikula
Nirovce
Nírovce
Ondrejovce
Oros
Oroska
Pastovce
Sakáloš
Setich
Sudov
Svätý Jur nad Hronom
Šalov
Tekovské Šarluhy
Tekovské Šarlužky
Trgyňa
Turá
Veľké Šarovce
Veľký Pesek
Vozokany nad Hronom
Zalaba
Želiezovce
Žemliary
-
Žilina
28. Októbra
Babkov
Bánová
Belá
Bitarová
Brezany
Budatín
Bytčianska Lehota
Bytčica
Čičmany
Divina
Divinka
Dolná Tižina
Ďurčiná
Fačkov
Frývald – Trstená
Gbelany
Horná Tižina
Hôrky
Chlumec nad Váhom
Jasenové
Kamenná Poruba
Kľače
Konská
Krasňany
Kukučínova
Kunerad
Lietava
Lietavská Lúčka
Lysica
Malá Čierna
Mojš
Mojšova Lúčka
Nededza
Nezbudská Lúčka
Ovčiarsko
Pivovarská
Podhorie
Poluvsie
Porubka
Rajec
Rosina
Stráňavy
Stránske
Stráža
Strážov
Strečno
Súnekova Závadka
Svederník
Svinná
Štefánikova
Šuja
Teplička nad Váhom
Terchová
Trnové
Turo
Varín
Veľká Čierna
Višňové
Zádubnie
Zástranie
Závodie
Zbyňov
Žilina